
 記者張杰倫報導
記者張杰倫報導
在人工智慧技術日新月異的今天,每個人或多或少都使用過ChatGPT、Claude或Gemini這類的大語言模型(LLM)。然而,AI的應用絕非僅止於「一問一答」。
AI應用的三級台階:你走到哪一步了?
要理解AI Agent,我們可以將其視為一條由淺入深的「三級台階」:
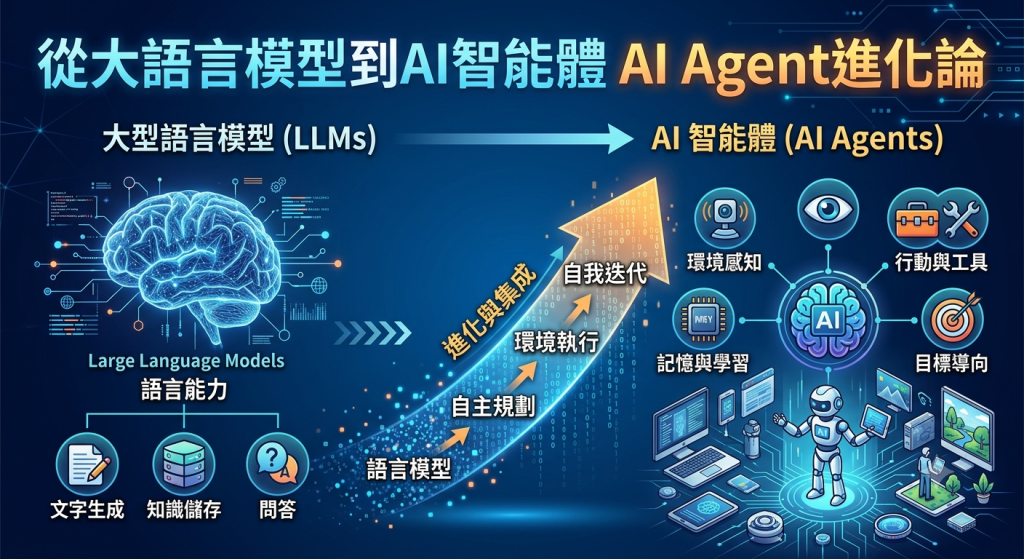
第一級台階是大語言模型(LLM)。這是最基礎的被動模式。你輸入一個問題,它輸出一個回答。例如,你請它幫忙撰寫一封請假信,它潤色完畢後輸出,任務即宣告結束。此模式有兩大局限:它不知道你的個人即時數據(如行程表),且它完全是被動的,你不提問,它絕不主動執行。
第二級台階是AI工作流(AI Workflow)。為了解決局限,人們開始將多個步驟串聯。例如,設定一個流程(如檢索增強生成,即RAG):當詢問工作任務時,AI會先去查看你的日曆與待辦清單,再彙整輸出。然而,在工作流中,所有的決策路徑都是人類提前設定好的。它就像火車只能在既定的軌道上行駛,缺乏自主應變的能力。
第三級台階則是AI Agent(AI智能體)。這是本質上的飛躍,最核心的改變在於:做決定的人,從人類變成了AI。以寫週報為例,在工作流中,你需要指定它去哪裡抓資料、用什麼模版;而在Agent模式下,你只需給它一個目標——「寫好本週週報」,它便會運用「推理加行動」(ReAct)的能力,自己思考最佳的抓取管道、自我判斷內容是否完整,甚至主動呼叫另一個AI進行審核與反覆迭代,直到滿意為止。
搭建AI Agent的三塊積木與四種模式
吳恩達將搭建AI Agent的架構拆解為三塊核心積木:模型(負責思考的主腦)、工具(負責幹活的手腳),以及多數人最容易忽略的評估(負責打分的教練)。例如,一個電商自動客服Agent,大腦模型負責理解客人的換貨需求,而手腳工具則負責連接後台系統查庫存、發送訊息。
有了積木,該如何組合?課程中提出了四種設計模式:
1 反思模式(Reflection):讓AI做完一遍後,自我審視、找出遺漏並修改,通常第二版的效果會顯著提升。
2 工具使用模式(Tool Use):引入統一標準(如MCP協議),讓Agent能自主調用外部搜索、訂位或數據庫工具,延伸大腦的邊界。
3 規劃模式(Planning):面對沒有固定流程的複雜任務(如在特定預算內規劃機票),讓Agent自行制定多步驟計劃並執行。
4 多智能體模式(Multi-Agent):將大任務拆解,讓不同的專職Agent協同運作(如選題Agent、寫稿Agent、SEO優化Agent各自負責擅長領域),發揮團隊作戰的最大效益。
成功的另一半:不可或缺的「評估」環節
許多人在搭建完Agent後便覺得大功告成,但吳恩達強調:「評估是搭建AI Agent的另外一半。」
如果你做了一個會議紀要Agent,經過測試才可能發現它在某些特定語境下會把「已完成事項」與「待辦事項」搞混。沒有評估,錯誤的資訊就會直接發送給團隊。透過測試十到二十個不同類型的極端例子,找出Agent表現比人類差的弱點,才能針對性地優化提示詞或調整流程,這才是品質精進的關鍵。
邁向AI Agent時代的行動清單其實很簡單:先從你日常重複的簡單任務(如整理郵件、寫週報)開始,利用現成的自動化工具(如make.com、n8n)試著搭出一個AI工作流;接著,嘗試放手讓AI做更多決策、挑選工具,並嚴格進行測試與評估。記住,重點是「先做出來,再追求做好」,在反覆的迭代中,你也能擁有專屬的高效AI特遣隊。
資料來源維基百科